Forscher bei Carnegie Mellon Universität haben ein System getestet, das mithilfe von Wi-Fi-Signalen die Position und Pose von Menschen in einem Raum bestimmt. In den Tests wurden gewöhnliche Wi-Fi-Router, insbesondere TP-Link Archer A7 AC1750-Geräte, an beiden Enden des Raums zusammen mit einer unterschiedlichen Anzahl von Personen im Raum positioniert. KI-gestützte Algorithmen analysierten die von den Menschen erzeugten Wi-Fi-Signalstörungen.
Wireframe-Bilder, die aus der Wi-Fi-Überwachung generiert wurden, sahen bei den Forschern in den meisten Fällen ziemlich genau aus behaupten dass die Schätzungen so gut sind wie einige „bildbasierte Ansätze“. Es gibt auch einige Vorteile und Attraktionen für die Verwendung von Wi-Fi über Kameras. Erstens respektieren die Wireframe-Schätzungen der menschlichen Pose die menschliche Privatsphäre mehr. Zweitens benötigt die Wi-Fi-basierte Wahrnehmung kein Licht und ist in der Lage, Körperhaltungen zu erkennen, selbst wenn sich Objekte im Weg befinden, die eine herkömmliche Kameraansicht verdecken würden. Ein weiterer großer Vorteil dieser Entdeckung ist, dass die verwendeten Wi-Fi-Router mit jeweils nur 30 US-Dollar billig und damit viel zugänglicher waren als teure und stromhungrige Lösungen wie Radar und LiDAR.
Bild 1 von 2

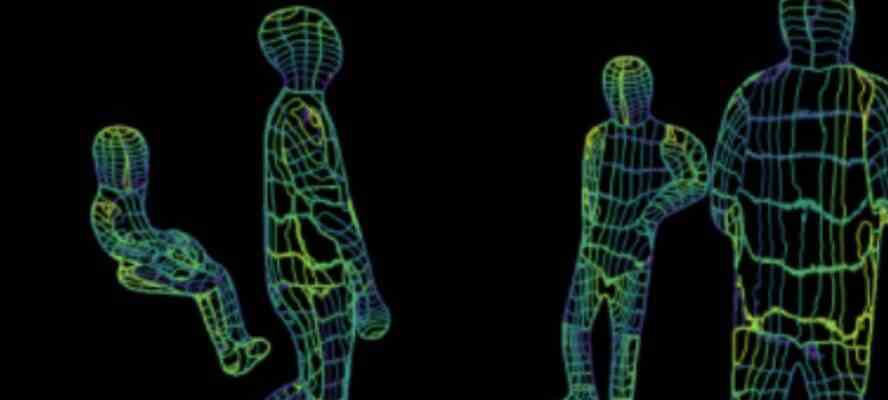
Oben sehen Sie eine Reihe synchronisierter Bilder mit den Videostandbildern auf der linken Seite und den von der KI generierten Drahtmodellen mit Wi-Fi-Erkennung auf der rechten Seite. Die Erkennung der Anzahl der Personen, Orte und Posen sieht sehr genau aus. Das von den Forschern von Carnegie Mellon veröffentlichte Papier liefert einige detaillierte Hintergrundinformationen dazu, wie dies gemacht wird. Kurz gesagt basiert die hier gezeigte Wi-Fi-basierte Wahrnehmungstechnologie auf Wi-Fi-Signalkanalzustandsinformationen (CSI), die das Verhältnis zwischen der gesendeten Signalwelle und der empfangenen Signalwelle darstellen. Diese Daten werden mithilfe einer Computer-Vision-versierten neuronalen Netzwerkarchitektur verarbeitet, die eine dichte Posenschätzung durchführen kann. Um die Generierung der menschlichen Darstellungen im Drahtgitterstil zu vereinfachen und damit zu beschleunigen, zerlegten die Forscher die menschliche Form in 24 Segmente.
Die Forscher geben zu, dass die oben skizzierte Methode zur Erkennung von Menschen und ihrer Positionierung / Posen nicht ohne Probleme ist, und sie sehen immer noch einige offensichtliche Fehler in Testszenarien. Sie stellten gnädigerweise einige Vergleichsbilder zur Verfügung, die „Fehlerfälle“ zeigen, die sie Problemen wie Menschen zuschreiben, die ungewöhnliche Posen einnehmen, und dass sich zu viele Personen gleichzeitig im Raum befinden (die Engine unterstützt optimal drei oder weniger Personen).

Es gibt noch viel zu tun, wobei die Forscher vorschlagen, dass die skizzierte Technik auf verschiedene Weise verbessert werden könnte, aber hauptsächlich durch bessere öffentliche Trainingsdaten für die WLAN-basierte Wahrnehmung, insbesondere in verschiedenen Raumlayouts. Obwohl es als datenschutzsensible Methode zur Überwachung der Sicherheit allein lebender alter Menschen angepriesen wird und eine sehr erschwingliche Lösung für diesen Zweck darstellt, werden einige zweifellos besorgt sein über die neue Bedrohung durch ihren Wi-Fi-Router, der sie ausspioniert.