
Ein MIT-Spinoff, mitbegründet von der Robotik-Koryphäe Daniela Rus, zielt darauf ab, Allzweck-KI-Systeme zu bauen, die auf einem relativ neuen Typ von KI-Modellen basieren, die als flüssiges neuronales Netzwerk bezeichnet werden.
Das Spin-off, treffend benannt Flüssige KItauchte heute Morgen aus der Tarnung auf und gab bekannt, dass es 37,5 Millionen US-Dollar – eine beachtliche Summe für eine zweistufige Seed-Runde – von VCs und Organisationen wie OSS Capital, PagsGroup, der WordPress-Muttergesellschaft Automattic, Samsung Next, Bold Capital Partners und ISAI Cap Venture eingesammelt hat. sowie Angel-Investoren wie GitHub-Mitbegründer Tom Preston Werner, Shopify-Mitbegründer Tobias Lütke und Red Hat-Mitbegründer Bob Young.
Die Tranche bewertet Liquid AI post-money mit 303 Millionen US-Dollar.
Zu Rus gehören Ramin Hasani (CEO), Mathias Lechner (CTO) und Alexander Amini (Chief Scientific Officer) zum Gründungsteam von Liquid AI. Hasani war zuvor leitender KI-Wissenschaftler bei Vanguard, bevor er als Postdoktorand und wissenschaftlicher Mitarbeiter zum MIT kam, während Lechner und Amini langjährige MIT-Forscher sind und – zusammen mit Hasani und Rus – zur Erfindung flüssiger neuronaler Netze beigetragen haben.
Sie fragen sich vielleicht, was flüssige neuronale Netze sind? Mein Kollege Brian Heater hat ausführlich darüber geschrieben, und ich empfehle Ihnen dringend, sein aktuelles Interview mit Rus zu diesem Thema zu lesen. Aber ich werde mein Bestes tun, um die wichtigsten Punkte abzudecken.
Eine Forschungsarbeit mit dem Titel „Flüssige zeitkonstante Netzwerke„, das Ende 2020 von Hasani, Rus, Lechner, Amini und anderen veröffentlicht wurde, brachte flüssige neuronale Netze nach mehreren Jahren des Hin und Her auf die Landkarte; Flüssige neuronale Netze als Konzept gibt es seit 2018.
Bildnachweis: MIT CSAIL
„Die Idee wurde ursprünglich an der Technischen Universität Wien, Österreich, im Labor von Professor Radu Grosu erfunden, wo ich meinen Ph.D. abgeschlossen habe. und Mathias Lechner seinen Master-Abschluss“, sagte Hasani gegenüber TechCrunch in einem E-Mail-Interview. „Die Arbeit wurde dann in Rus‘ Labor am MIT CSAIL verfeinert und skaliert, wo Amini und Rus sich Mathias und mir anschlossen.“
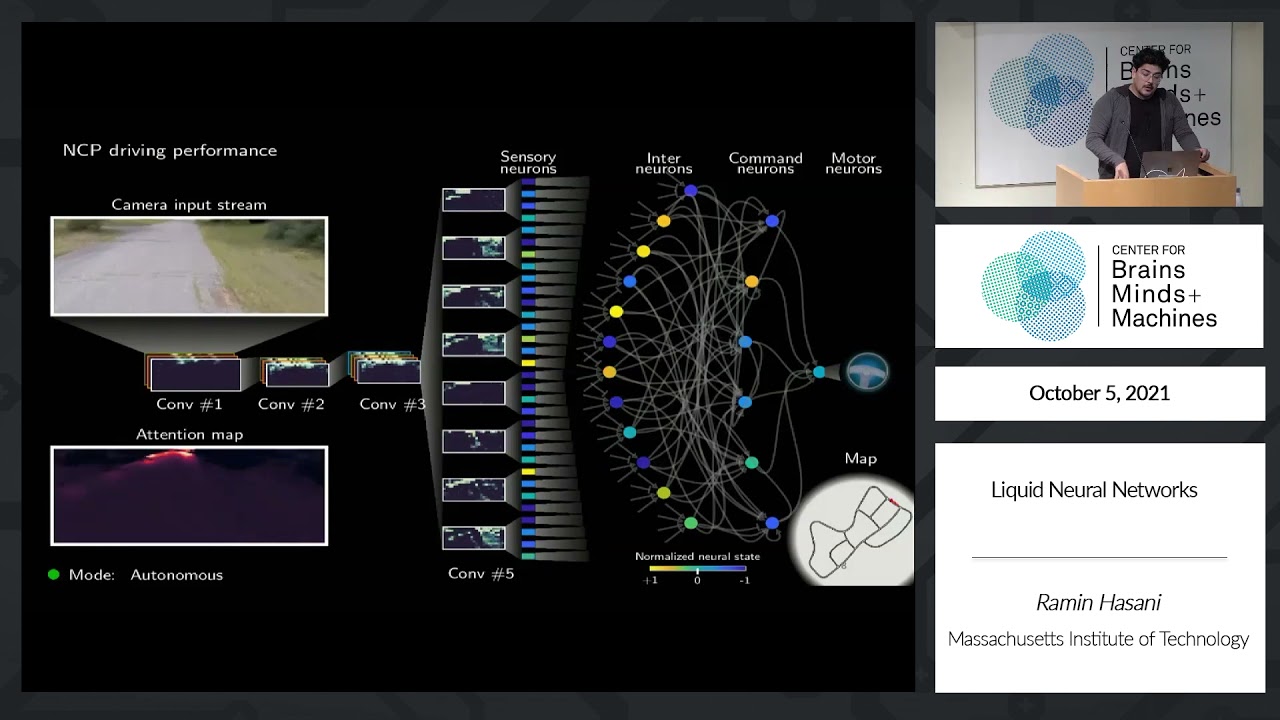
Flüssige neuronale Netze bestehen aus „Neuronen“, die wie die meisten anderen modernen Modellarchitekturen durch Gleichungen gesteuert werden, die das Verhalten jedes einzelnen Neurons über die Zeit vorhersagen. Das „flüssige“ Bit im Begriff „flüssige neuronale Netze“ bezieht sich auf die Flexibilität der Architektur; Inspiriert durch die „Gehirne“ von Spulwürmern sind flüssige neuronale Netze nicht nur viel kleiner als herkömmliche KI-Modelle, sie benötigen auch weitaus weniger Rechenleistung für den Betrieb.
Ich denke, es ist hilfreich, ein flüssiges neuronales Netzwerk mit einem typischen generativen KI-Modell zu vergleichen.
GPT-3, der Vorgänger des textgenerierenden und bildanalysierenden OpenAI-Modells GPT-4, enthält etwa 175 Milliarden Parameter und etwa 50.000 Neuronen – „Parameter“ sind die Teile des Modells, die aus Trainingsdaten gelernt wurden und im Wesentlichen die Fähigkeiten des definieren Modell für ein Problem (im Fall von GPT-3 beim Generieren von Text). Im Gegensatz dazu kann ein flüssiges neuronales Netzwerk, das für eine Aufgabe wie das Navigieren einer Drohne durch eine Außenumgebung trainiert wurde, nur 20.000 Parameter und weniger als 20 Neuronen enthalten.
Im Allgemeinen bedeuten weniger Parameter und Neuronen, dass weniger Rechenleistung zum Trainieren und Ausführen des Modells erforderlich ist, eine attraktive Aussicht in einer Zeit, in der Die KI-Rechenkapazität ist knapp. Ein flüssiges neuronales Netzwerk, das zum autonomen Fahren eines Autos entwickelt wurde, könnte theoretisch auf einem Raspberry Pi laufen, um ein konkretes Beispiel zu nennen.
Die geringe Größe und die unkomplizierte Architektur flüssiger neuronaler Netze bieten den zusätzlichen Vorteil der Interpretierbarkeit. Es macht intuitiv Sinn – die Funktion jedes Neurons in einem flüssigen neuronalen Netzwerk herauszufinden ist eine leichter zu bewältigende Aufgabe als die Funktion der etwa 50.000 Neuronen in GPT-3 herauszufinden (obwohl es solche gab). einigermaßen erfolgreich Bemühungen um dies zu tun).
Mittlerweile gibt es bereits Modelle mit wenigen Parametern, die autonomes Fahren, Textgenerierung und mehr ermöglichen. Aber der geringe Overhead ist nicht das Einzige, was flüssige neuronale Netze auszeichnet.
Ein weiteres attraktives – und wohl einzigartigeres – Merkmal flüssiger neuronaler Netze ist ihre Fähigkeit, ihre Parameter im Laufe der Zeit an den „Erfolg“ anzupassen. Die Netzwerke berücksichtigen Datensequenzen im Gegensatz zu den isolierten Slices oder Schnappschüssen, die die meisten Modelle verarbeiten, und passen den Signalaustausch zwischen ihren Neuronen dynamisch an. Diese Eigenschaften ermöglichen es flüssigen neuronalen Netzen, mit Veränderungen in ihrer Umgebung und Umständen umzugehen, selbst wenn sie nicht darauf trainiert sind, diese Veränderungen zu antizipieren, wie etwa sich ändernde Wetterbedingungen im Kontext des autonomen Fahrens.
In Tests haben flüssige neuronale Netze andere hochmoderne Algorithmen bei der Vorhersage zukünftiger Werte in Datensätzen von der Atmosphärenchemie bis zum Autoverkehr überholt. Aber noch beeindruckender – zumindest für diesen Autor – ist, was sie bei der autonomen Navigation erreicht haben.
Anfang dieses Jahres trainierten Rus und der Rest des Liquid AI-Teams ein flüssiges neuronales Netzwerk anhand von Daten, die von einem professionellen menschlichen Drohnenpiloten gesammelt wurden. Anschließend setzten sie den Algorithmus auf einer Flotte von Quadrocoptern ein, die Langstrecken-, Zielverfolgungs- und anderen Tests in verschiedenen Außenumgebungen, darunter einem Wald und einem dichten Stadtviertel, unterzogen wurden.
Nach Angaben des Teams schlug das flüssige neuronale Netzwerk andere Modelle, die für die Navigation trainiert wurden, und schaffte es, Entscheidungen zu treffen, die die Drohnen auch bei Lärm und anderen Herausforderungen zu Zielen in bisher unerforschten Räumen führten. Darüber hinaus war das flüssige neuronale Netzwerk das einzige Modell, das ohne Feinabstimmung zuverlässig auf Szenarien verallgemeinern konnte, die es noch nicht gesehen hatte.
Die Suche und Rettung von Drohnen sowie die Überwachung und Lieferung von Wildtieren gehören zu den offensichtlicheren Anwendungen flüssiger neuronaler Netze. Aber Rus und der Rest des Liquid AI-Teams behaupten, dass die Architektur für die Analyse aller Phänomene geeignet ist, die im Laufe der Zeit schwanken, darunter Stromnetze, medizinische Anzeigen, Finanztransaktionen und Unwettermuster. Solange es einen Datensatz mit sequentiellen Daten, wie z. B. Videos, gibt, können flüssige neuronale Netze darauf trainieren.
Was genau macht Liquid AI? das Startup hoffen, mit dieser leistungsstarken neuen (ish) Architektur etwas zu erreichen? Schlicht und einfach: Kommerzialisierung.
„[We compete] mit Gründungsmodellunternehmen, die GPTs aufbauen“, sagte Hasani – ohne Namen zu nennen, aber nicht ganz so subtil auf OpenAI und seine vielen Konkurrenten (z. B. Anthropic, Stability AI, Cohere, AI21 Labs usw.) im Bereich der generativen KI hinzuweisen. „[The seed funding] wird es uns ermöglichen, die besten neuen Liquid-Foundation-Modelle ihrer Klasse zu entwickeln, die über GPTs hinausgehen.“
Man geht davon aus, dass auch die Arbeit an der Architektur des flüssigen neuronalen Netzwerks fortgesetzt wird. Erst im Jahr 2022, Rus’ Labor erdacht eine Möglichkeit, flüssige neuronale Netze weit über das hinaus zu skalieren, was früher rechnerisch praktisch war; Mit etwas Glück könnten weitere Durchbrüche am Horizont lauern.
Über das Entwerfen und Trainieren neuer Modelle hinaus plant Liquid AI die Bereitstellung einer lokalen und privaten KI-Infrastruktur für Kunden sowie einer Plattform, die es diesen Kunden ermöglicht, ihre eigenen Modelle für alle Anwendungsfälle zu erstellen – vorbehaltlich der Bedingungen von Liquid AI Kurs.
„Verantwortlichkeit und Sicherheit großer KI-Modelle sind von größter Bedeutung“, fügte Hasani hinzu. „Liquid AI bietet kapitaleffizientere, zuverlässigere, erklärbare und leistungsfähigere Modelle für maschinelles Lernen sowohl für domänenspezifische als auch für generative KI-Anwendungen.“
Liquid AI, das neben Boston auch in Palo Alto vertreten ist, verfügt über ein 12-köpfiges Team. Hasani erwartet, dass diese Zahl bis Anfang nächsten Jahres auf 20 ansteigt.