
Künstliche Intelligenz und Deep Learning sind heutzutage ständig in den Schlagzeilen, sei es ChatGPT, das schlechte Ratschläge generiert, selbstfahrende Autos, Künstler, denen der Einsatz von KI vorgeworfen wird, medizinischer Rat von KI und mehr. Die meisten dieser Tools verlassen sich auf komplexe Server mit viel Hardware für das Training, aber die Nutzung des trainierten Netzwerks per Inferenz kann auf Ihrem PC mit seiner Grafikkarte erfolgen. Aber wie schnell sind Verbraucher-GPUs für die KI-Inferenz?
Wir haben Stable Diffusion, einen beliebten KI-Bildgenerator, auf den neuesten GPUs von Nvidia, AMD und sogar Intel getestet, um zu sehen, wie sie sich schlagen. Wenn Sie zufällig versucht haben, Stable Diffusion auf Ihrem eigenen PC zum Laufen zu bringen, haben Sie vielleicht eine Ahnung, wie komplex – oder einfach! – das kann sein. Die kurze Zusammenfassung ist, dass Nvidias GPUs das Quartier beherrschen, wobei die meiste Software mit CUDA und anderen Nvidia-Toolsets entwickelt wurde. Aber das bedeutet nicht, dass Sie Stable Diffusion nicht auf den anderen GPUs ausführen können.
Am Ende haben wir drei verschiedene Stable Diffusion-Projekte für unsere Tests verwendet, hauptsächlich weil kein einzelnes Paket auf jeder GPU funktionierte. Für Nvidia haben wir uns entschieden Webui-Version von Automatic 1111 (öffnet in neuem Tab). AMD GPUs wurden mit getestet Die Shark-Version von Nod.ai (öffnet in neuem Tab)während wir für Intels Arc-GPUs verwendet haben Stabile Diffusion OpenVINO (öffnet in neuem Tab). Haftungsausschlüsse sind in Ordnung. Wir haben keines dieser Tools codiert, aber wir haben nach Dingen gesucht, die leicht zum Laufen zu bringen waren (unter Windows), und die auch einigermaßen optimiert zu sein schienen.
Wir sind relativ zuversichtlich, dass die Tests der Nvidia 30-Serie gute Arbeit leisten, um eine nahezu optimale Leistung zu extrahieren – insbesondere wenn xformers aktiviert ist, was eine zusätzliche Leistungssteigerung von ca. 20 % bietet. Die Ergebnisse der RTX 40-Serie sind unterdessen etwas niedriger als erwartet, möglicherweise aufgrund fehlender Optimierungen für die neue Ada Lovelace-Architektur.
Die AMD-Ergebnisse sind auch ein bisschen gemischt, aber sie sind das Gegenteil der Nvidia-Situation: RDNA-3-GPUs funktionieren recht gut, während die RDNA-2-GPUs eher mittelmäßig erscheinen. Schließlich ist auf Intel-GPUs, obwohl die ultimative Leistung anständig mit den AMD-Optionen übereinzustimmen scheint, die Zeit zum Rendern in der Praxis wesentlich länger – wahrscheinlich passiert eine Menge zusätzlicher Hintergrundkram, der sie verlangsamt.
Wir verwenden auch Stable Diffusion 1.4-Modelle anstelle der neueren SD 2.0 oder 2.1, vor allem, weil es viel mehr Arbeit erfordert hätte, SD2.1 auf Nicht-Nvidia-Hardware zum Laufen zu bringen (z. B. lernen, Code zu schreiben, um Unterstützung zu ermöglichen). Wenn Sie jedoch einige Insiderkenntnisse über Stable Diffusion haben und andere Open-Source-Projekte empfehlen möchten, die möglicherweise besser laufen als das, was wir verwendet haben, teilen Sie uns dies in den Kommentaren mit (oder senden Sie einfach eine E-Mail an Jarred (öffnet in neuem Tab)).
Bild 1 von 11

Unsere Testparameter sind für alle GPUs gleich, obwohl es in der Intel-Version keine Optionen für eine negative Eingabeaufforderungsoption gibt (zumindest nicht, dass wir sie finden könnten). Die obige Galerie wurde mit der Nvidia-Version erstellt, mit Ausgaben mit höherer Auflösung (die viel Zeit in Anspruch nehmen, viel länger zu vervollständigen). Es sind die gleichen Eingabeaufforderungen, aber das Ziel ist 2048 x 1152 statt der 512 x 512, die wir für unsere Benchmarks verwendet haben. Hier die entsprechenden Einstellungen:
Positive Aufforderung:
postapokalyptische Steampunk-Stadt, Erforschung, filmisch, realistisch, hyperdetailliert, fotorealistische maximale Details, volumetrisches Licht, (((Fokus))), Weitwinkel, (((hell erleuchtet))), (((Vegetation))), Blitz , Reben, Zerstörung, Verwüstung, vom Krieg zerrissen, Ruinen
Negative Aufforderung:
(((verschwommen))), ((neblig)), (((dunkel))), ((monochrom)), Sonne, (((Schärfentiefe)))
Schritte:
100
Klassifikatorfreie Anleitung:
15.0
Abtastalgorithmus:
Einige Euler-Varianten (Ancestral, Discrete)
Der Abtastalgorithmus scheint die Leistung nicht wesentlich zu beeinträchtigen, obwohl er die Ausgabe beeinträchtigen kann. Automatic 1111 bietet die meisten Optionen, während der Intel OpenVINO-Build Ihnen keine Wahl lässt.
Hier sind die Ergebnisse unserer Tests der GPUs der AMD RX 7000/6000-Serie, der Nvidia RTX 40/30-Serie und der Intel Arc A-Serie. Beachten Sie, dass jede Nvidia-GPU zwei Ergebnisse hat, eines mit dem Standard-Rechenmodell (langsamer und in Schwarz) und ein zweites mit dem schnellere “xformers”-Bibliothek von Facebook (öffnet in neuem Tab) (schneller und grün).
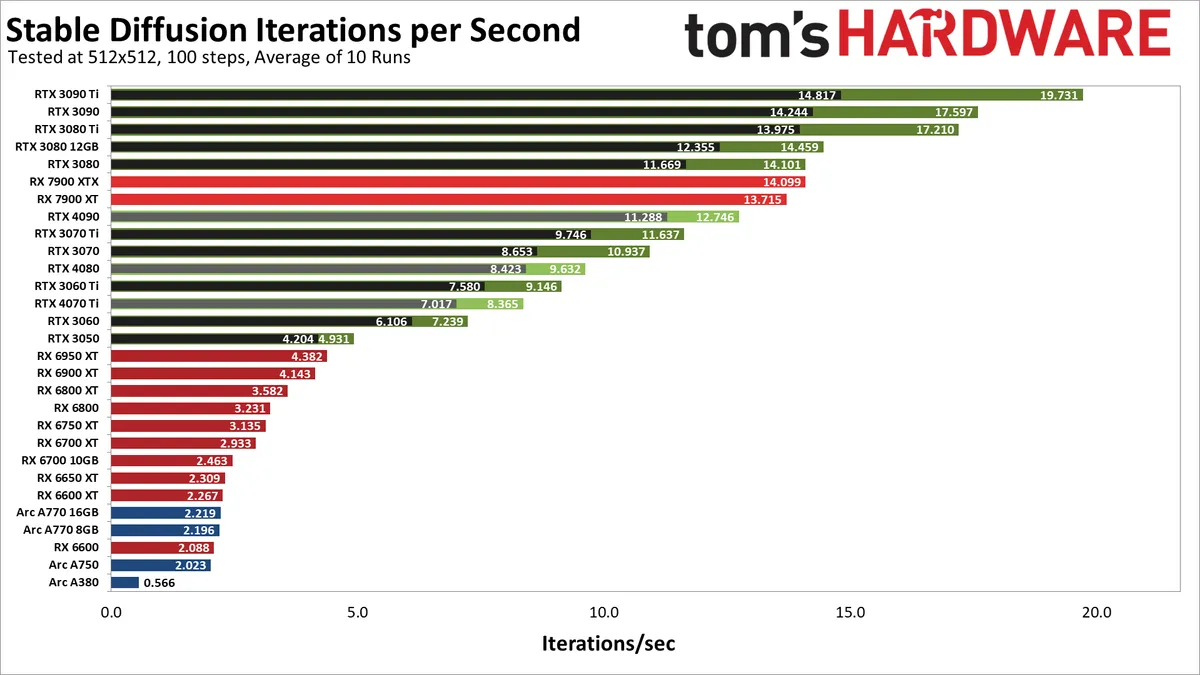
Wie erwartet liefern die GPUs von Nvidia eine überlegene Leistung – manchmal mit deutlichem Vorsprung – als alles von AMD oder Intel. Es gibt jedoch eindeutig einige Anomalien. Die schnellste GPU in unseren ersten Tests ist die RTX 3090 Ti, die mit fast 20 Iterationen pro Sekunde oder etwa fünf Sekunden pro Bild unter Verwendung der konfigurierten Parameter die Spitze erreicht. Von da an fallen die Dinge ab, aber selbst der RTX 3080 knüpft im Grunde an AMDs neue RX 7900 XTX an, und der RTX 3050 übertrifft den RX 6950 XT. Aber lasst uns über die Kuriositäten sprechen.
Erstens erwarteten wir, dass der RTX 4090 die Konkurrenz vernichten würde, und das ist eindeutig nicht geschehen. Tatsächlich ist es langsamer als AMDs 7900 XT und auch langsamer als die RTX 3080. In ähnlicher Weise landet die RTX 4080 zwischen der 3070 und 3060 Ti, während die RTX 4070 Ti zwischen der 3060 und 3060 Ti sitzt.
Richtige Optimierungen könnten die Leistung der Karten der RTX 40-Serie leicht verdoppeln. In Anbetracht der erheblichen Leistungslücke zwischen der RX 7900 XT und der RX 6950 XT könnten ihre Optimierungen in ähnlicher Weise auch die Leistung der RDNA 2-GPUs verdoppeln. Das ist nur eine ungefähre Vermutung, basierend auf dem, was wir in unserer GPU-Benchmark-Hierarchie gesehen haben, aber diese ersten Ergebnisse haben definitiv etwas Seltsames.
Intels Arc-GPUs liefern derzeit sehr enttäuschende Ergebnisse, zumal sie XMX (Matrix)-Operationen unterstützen, die bis zu 4-mal so viel Durchsatz liefern sollen wie reguläre FP32-Berechnungen. Wir vermuten, dass das aktuelle Stable Diffusion OpenVINO-Projekt, das wir verwendet haben, ebenfalls viel Raum für Verbesserungen lässt. Übrigens, wenn Sie versuchen möchten, SD auf einer Arc-GPU auszuführen, beachten Sie, dass Sie die Datei „stable_diffusion_engine.py“ bearbeiten und „CPU“ in „GPU“ ändern müssen – sonst werden die Grafikkarten nicht für die Berechnungen verwendet und dauert wesentlich länger.
Zurück zu den Ergebnissen. Mit den angegebenen Versionen schneiden die Karten der RTX 30-Serie von Nvidia hervorragend ab, die Karten der RX 7000-Serie von AMD sind hervorragend, die RTX 40-Serie ist unterdurchschnittlich, die RX 6000-Serie ist wirklich unterdurchschnittlich und Arc-GPUs sehen im Allgemeinen schlecht aus. Die Dinge könnten sich mit aktualisierter Software radikal ändern, und angesichts der Popularität von KI erwarten wir, dass es nur eine Frage der Zeit ist, bis wir eine bessere Abstimmung sehen (oder das richtige Projekt finden, das bereits auf eine bessere Leistung abgestimmt ist).
Auch hier ist nicht klar, wie genau diese Projekte optimiert sind, aber es könnte interessant sein, sich die maximale theoretische Leistung (TFLOPS) der verschiedenen GPUs anzusehen. Das folgende Diagramm zeigt die theoretische FP16-Leistung für jede GPU, gegebenenfalls unter Verwendung von Tensor-/Matrixkernen.

Diese Tensor-Kerne auf Nvidia haben zumindest theoretisch eine klare Schlagkraft, obwohl unsere Stable Diffusion-Tests offensichtlich nicht genau mit diesen Zahlen übereinstimmen. Beispielsweise ist die RTX 4090 (mit FP16) auf dem Papier bis zu 106 % schneller als die RTX 3090 Ti, während sie in unseren Tests 35 % langsamer war. Beachten Sie auch, dass wir davon ausgehen, dass das von uns verwendete Stable Diffusion-Projekt (Automatic 1111) nicht einmal versucht, die neuen FP8-Anweisungen auf Ada Lovelace-GPUs zu nutzen, die möglicherweise die Leistung der RTX 40-Serie erneut verdoppeln könnten.
Schauen Sie sich in der Zwischenzeit die Arc-GPUs an. Ihre Matrixkerne sollten mehr oder weniger eine ähnliche Leistung wie die RTX 3060 Ti und RX 7900 XTX bieten, wobei die A380 um die RX 6800 nach unten geht. In der Praxis sind Arc-GPUs bei weitem nicht in der Nähe dieser Werte. Die schnellsten A770-GPUs landen zwischen der RX 6600 und der RX 6600 XT, die A750 fällt knapp hinter die RX 6600 und die A380 ist etwa ein Viertel so schnell wie die A750. Sie sind also alle etwa ein Viertel der erwarteten Leistung, was sinnvoll wäre, wenn die XMX-Kerne nicht verwendet werden.
Die Verhältnisse auf Arc sehen jedoch ungefähr richtig aus. Die theoretische Rechenleistung des A380 beträgt etwa ein Viertel der A750. Höchstwahrscheinlich verwenden sie Shader für die Berechnungen im FP32-Modus mit voller Präzision und verpassen einige zusätzliche Optimierungen.
Die andere bemerkenswerte Sache ist, dass sich die theoretische Berechnung auf AMDs RX 7900 XTX/XT im Vergleich zur RX 6000-Serie stark verbessert hat und die Speicherbandbreite kein kritischer Faktor ist – die 3080 10-GB- und 12-GB-Modelle landen relativ nahe beieinander. Vielleicht sind die obigen AMD-Ergebnisse also nicht völlig ausgeschlossen, da der 7900 XTX im Vergleich zum 6950 XT fast das Dreifache an Rohrechenleistung leistet. Abgesehen davon, dass der 7900 XT fast so gut abschneidet wie der XTX, wo die Rohdatenverarbeitung den XTX um etwa 19 % begünstigen sollte, anstatt der von uns gemessenen 3 %.
Letztendlich ist dies eher eine Momentaufnahme der Stable Diffusion-Leistung auf AMD-, Intel- und Nvidia-GPUs als eine echte Leistungsaussage. Mit vollständigen Optimierungen sollte die Leistung eher wie das theoretische TFLOPS-Diagramm aussehen, und sicherlich sollten neuere Karten der RTX 40-Serie nicht hinter vorhandene Teile der RTX 30-Serie zurückfallen.

Das bringt uns zu einem letzten Diagramm, wo wir einige Tests mit höherer Auflösung durchgeführt haben. Wir haben noch nicht alle neuen GPUs getestet und Linux auf den von uns getesteten Karten der AMD RX 6000-Serie verwendet. Aber es sieht so aus, als würde die komplexere Zielauflösung von 2048 x 1152 zumindest die RTX 4090 besser ausnutzen. Wir werden sehen, ob wir dieses Thema im kommenden Jahr öfter aufgreifen.