
Stability AI, das durch Wagniskapital finanzierte Startup hinter dem Text-to-Image-KI-System Stable Diffusion, finanziert eine weitreichende Anstrengung, um KI an den Grenzen der Biotechnologie anzuwenden. Genannt OpenBioMLkonzentrieren sich die ersten Projekte des Unterfangens auf auf maschinellem Lernen basierende Ansätze zur DNA-Sequenzierung, Proteinfaltung und rechnergestützten Biochemie.
Die Gründer des Unternehmens beschreiben OpenBioML als ein „offenes Forschungslabor“ – und zielen darauf ab, die Schnittmenge von KI und Biologie in einem Umfeld zu erforschen, in dem Studenten, Fachleute und Forscher teilnehmen und zusammenarbeiten können, so Emad Mostaque, CEO von Stability AI.
„OpenBioML ist eine der unabhängigen Forschungsgemeinschaften, die Stability unterstützt“, sagte Mostaque in einem E-Mail-Interview mit TechCrunch. „Stabilität zielt darauf ab, KI zu entwickeln und zu demokratisieren, und durch OpenBioML sehen wir eine Gelegenheit, den Stand der Technik in Wissenschaft, Gesundheit und Medizin voranzutreiben.“
Angesichts der Kontroverse um Stable Diffusion – das KI-System von Stability AI, das Kunst aus Textbeschreibungen generiert, ähnlich wie DALL-E 2 von OpenAI – könnte man verständlicherweise misstrauisch gegenüber dem ersten Vorstoß von Stability AI im Gesundheitswesen sein. Das Startup verfolgt bei der Governance einen Laissez-faire-Ansatz, der es Entwicklern ermöglicht, das System nach Belieben zu verwenden, einschließlich für Deepfakes und Pornografie von Prominenten.
Stabilität Abgesehen von den bisherigen ethisch fragwürdigen Entscheidungen der KI ist maschinelles Lernen in der Medizin ein Minenfeld. Während die Technologie unter anderem erfolgreich zur Diagnose von Erkrankungen wie Haut- und Augenkrankheiten eingesetzt wurde, hat die Forschung gezeigt, dass Algorithmen Verzerrungen entwickeln können, die bei einigen Patienten zu einer schlechteren Versorgung führen. Ein April 2021 lernenstellte beispielsweise fest, dass statistische Modelle zur Vorhersage des Suizidrisikos bei Patienten mit psychischer Gesundheit bei weißen und asiatischen Patienten gut abschneiden, bei schwarzen Patienten jedoch schlecht.
OpenBioML beginnt mit Bedacht auf sichererem Terrain. Seine ersten Projekte sind:
- BioLMdas darauf abzielt, Techniken der Verarbeitung natürlicher Sprache (NLP) auf die Gebiete der Computerbiologie und -chemie anzuwenden
- DNA-Diffusiondas darauf abzielt, KI zu entwickeln, die DNA-Sequenzen aus Texteingabeaufforderungen generieren kann
- LibreFolddas darauf abzielt, den Zugang zu KI-Proteinstruktur-Vorhersagesystemen zu verbessern, die dem AlphaFold 2 von DeepMind ähneln
Jedes Projekt wird von unabhängigen Forschern geleitet, aber Stability AI bietet Unterstützung in Form des Zugriffs auf seinen von AWS gehosteten Cluster mit über 5.000 Nvidia A100-GPUs, um die KI-Systeme zu trainieren. Laut Niccolò Zanichelli, einem Informatikstudenten an der Universität Parma und einem der leitenden Forscher an OpenBioML, das wird sein genügend Rechenleistung und Speicherplatz, um schließlich bis zu 10 verschiedene AlphaFold 2-ähnliche Systeme parallel zu trainieren.
„Viel Forschung in der Computerbiologie führt bereits zu Open-Source-Veröffentlichungen. Vieles davon geschieht jedoch auf der Ebene eines einzelnen Labors und wird daher normalerweise durch unzureichende Rechenressourcen eingeschränkt“, sagte Zanichelli per E-Mail gegenüber TechCrunch. „Wir wollen dies ändern, indem wir groß angelegte Kooperationen fördern und dank der Unterstützung von Stability AI diese Kooperationen mit Ressourcen unterstützen, zu denen nur die größten Industrielabore Zugang haben.“
Generieren von DNA-Sequenzen
Von Die laufenden Projekte von OpenBioML, DNA-Diffusion – geleitet vom Labor des Pathologieprofessors Luca Pinello am Massachusetts General Hospital & Harvard Medical School – ist vielleicht das ehrgeizigste. Ziel ist es, mithilfe generativer KI-Systeme die Regeln „regulatorischer“ DNA-Sequenzen oder Segmente von Nukleinsäuremolekülen, die die Expression bestimmter Gene in einem Organismus beeinflussen, zu lernen und anzuwenden. Viele Krankheiten und Störungen sind das Ergebnis fehlregulierter Gene, aber die Wissenschaft muss noch einen zuverlässigen Prozess zur Identifizierung – geschweige denn zur Veränderung – dieser regulatorischen Sequenzen finden.
DNA-Diffusion schlägt vor, eine Art KI-System zu verwenden, das als Diffusionsmodell bekannt ist, um zelltypspezifische regulatorische DNA-Sequenzen zu erzeugen. Diffusionsmodelle – die Bildgeneratoren wie Stable Diffusion und DALL-E 2 von OpenAI untermauern – erzeugen neue Daten (z. B. DNA-Sequenzen), indem sie lernen, wie viele vorhandene Datenproben zerstört und wiederhergestellt werden können. Wenn sie mit den Samples gefüttert werden, werden die Modelle besser darin, alle Daten wiederherzustellen, die sie zuvor zerstört hatten, um neue Werke zu erstellen.

Bildnachweis: OpenBioML
„Die Diffusion hat sich in multimodalen generativen Modellen als weit verbreiteter Erfolg erwiesen und wird nun in der Computerbiologie angewendet, beispielsweise zur Erzeugung neuartiger Proteinstrukturen“, sagte Zanichelli. „Mit DNA-Diffusion untersuchen wir jetzt ihre Anwendung auf genomische Sequenzen.“
Wenn alles nach Plan läuft, wird das DNA-Diffusion-Projekt ein Diffusionsmodell erstellen, das regulatorische DNA-Sequenzen aus Textanweisungen wie „Eine Sequenz, die ein Gen in Zelltyp X auf seine maximale Expressionsstufe aktiviert“ und „Eine Sequenz, die aktiviert ein Gen in Leber und Herz, aber nicht im Gehirn.“ Ein solches Modell könnte laut Zanichelli auch dabei helfen, die Komponenten regulatorischer Sequenzen zu interpretieren – und das Verständnis der wissenschaftlichen Gemeinschaft für die Rolle regulatorischer Sequenzen bei verschiedenen Krankheiten verbessern.
Es ist erwähnenswert, dass dies weitgehend theoretisch ist. Während vorläufige Forschungen zur Anwendung von Diffusion auf die Proteinfaltung scheinen vielversprechendes ist noch sehr früh, gibt Zanichelli zu – daher der Drang, die breitere KI-Community einzubeziehen.
Vorhersage von Proteinstrukturen
LibreFold von OpenBioML ist zwar kleiner, trägt aber eher sofortige Früchte. Das Projekt zielt darauf ab, ein besseres Verständnis von maschinellen Lernsystemen zu erlangen, die Proteinstrukturen vorhersagen, sowie Möglichkeiten, diese zu verbessern.
Wie mein Kollege Devin Coldewey in seinem Artikel über die Arbeit von DeepMind an AlphaFold 2 behandelte, sind KI-Systeme, die die Proteinform genau vorhersagen, relativ neu in der Szene, aber in Bezug auf ihr Potenzial transformativ. Proteine bestehen aus Sequenzen von Aminosäuren, die sich zu Formen falten, um verschiedene Aufgaben in lebenden Organismen zu erfüllen. Der Prozess der Bestimmung, welche Form eine Säuresequenz erzeugen wird, war einst ein mühsames, fehleranfälliges Unterfangen. KI-Systeme wie AlphaFold 2 haben das geändert; Dank ihnen sind der Wissenschaft heute über 98 % der Proteinstrukturen im menschlichen Körper sowie Hunderttausende anderer Strukturen in Organismen wie E. coli und Hefe bekannt.
Nur wenige Gruppen verfügen jedoch über das technische Fachwissen und die Ressourcen, die für die Entwicklung dieser Art von KI erforderlich sind. DeepMind verbrachte Tage damit, AlphaFold 2 auf Tensor Processing Units (TPUs), Googles teurer KI-Beschleuniger-Hardware, zu trainieren. Und Säuresequenz-Trainingsdatensätze sind oft urheberrechtlich geschützt oder werden unter nichtkommerziellen Lizenzen veröffentlicht.
Proteine, die sich in ihre dreidimensionale Struktur falten. Bildnachweis: Christoph Burgstedt/Science Photo Library/Getty Images
„Das ist schade, denn wenn Sie sich ansehen, was die Community auf dem von DeepMind veröffentlichten AlphaFold 2-Checkpoint aufbauen konnte, ist das einfach unglaublich“, sagte Zanichelli und bezog sich auf das trainierte AlphaFold 2-Modell, das DeepMind letztes Jahr veröffentlichte . „Beispielsweise berichtete Minkyung Baek, Professor an der Seoul National University, nur wenige Tage nach der Veröffentlichung auf Twitter über einen Trick, der es dem Modell ermöglichte, Vorhersagen zu treffen Quartäre Strukturen – etwas, von dem nur wenige, wenn überhaupt jemand, erwartet hat, dass das Modell dazu in der Lage ist. Es gibt noch viele weitere Beispiele dieser Art, also wer weiß, was die breitere wissenschaftliche Gemeinschaft aufbauen könnte, wenn sie in der Lage wäre, völlig neue AlphaFold-ähnliche Vorhersagemethoden für Proteinstrukturen zu trainieren?“
Aufbauend auf der Arbeit von RoseTTAFold und OpenFold, zwei laufenden Community-Bemühungen zur Replikation von AlphaFold 2, LibreFold wird „groß angelegte“ Experimente mit verschiedenen Proteinfaltungsvorhersagesystemen ermöglichen. Unter der Leitung von Forschern des University College London, Harvard und Stockholm wird sich LibreFold laut Zanichelli darauf konzentrieren, ein besseres Verständnis dafür zu erlangen, was die Systeme leisten können und warum.
„LibreFold ist im Kern ein Projekt für die Community, von der Community. Das Gleiche gilt für die Veröffentlichung sowohl der Modellprüfpunkte als auch der Datensätze, da es nur ein oder zwei Monate dauern könnte, bis wir mit der Veröffentlichung der ersten Ergebnisse beginnen, oder es könnte erheblich länger dauern“, sagte er. “Meine Intuition ist jedoch, dass Ersteres wahrscheinlicher ist.”
Anwendung von NLP auf die Biochemie
Auf einem längeren Zeithorizont steht OpenBioMLs BioLM-Projekt, das die vagere Mission hat, „vom NLP abgeleitete Sprachmodellierungstechniken auf biochemische Sequenzen anzuwenden“. In Zusammenarbeit mit EleutherAI, einer Forschungsgruppe, die mehrere Open-Source-Textgenerierungsmodelle veröffentlicht hat, hofft BioLM, neue „biochemische Sprachmodelle“ für eine Reihe von Aufgaben zu trainieren und zu veröffentlichen, darunter die Generierung von Proteinsequenzen.
Zanichelli zeigt auf Salesforce ProGen als Beispiel für die Arten von Arbeiten, die BioLM in Angriff nehmen könnte. ProGen behandelt Aminosäuresequenzen wie Wörter in einem Satz. Das Modell, das auf einem Datensatz von mehr als 280 Millionen Proteinsequenzen und zugehörigen Metadaten trainiert wurde, sagt die nächste Gruppe von Aminosäuren aus den vorherigen voraus, wie ein Sprachmodell, das das Ende eines Satzes von seinem Anfang vorhersagt.
Nvidia hat Anfang dieses Jahres ein Sprachmodell veröffentlicht, MegaMolBART, das auf einem Datensatz von Millionen von Molekülen trainiert wurde, um nach potenziellen Wirkstoffzielen zu suchen und chemische Reaktionen vorherzusagen. Meta auch vor kurzem ausgebildet ein NLP namens ESM-2 auf Sequenzen von Proteinen, ein Ansatz, der es dem Unternehmen nach eigenen Angaben ermöglichte, Sequenzen für mehr als 600 Millionen Proteine in nur zwei Wochen vorherzusagen.
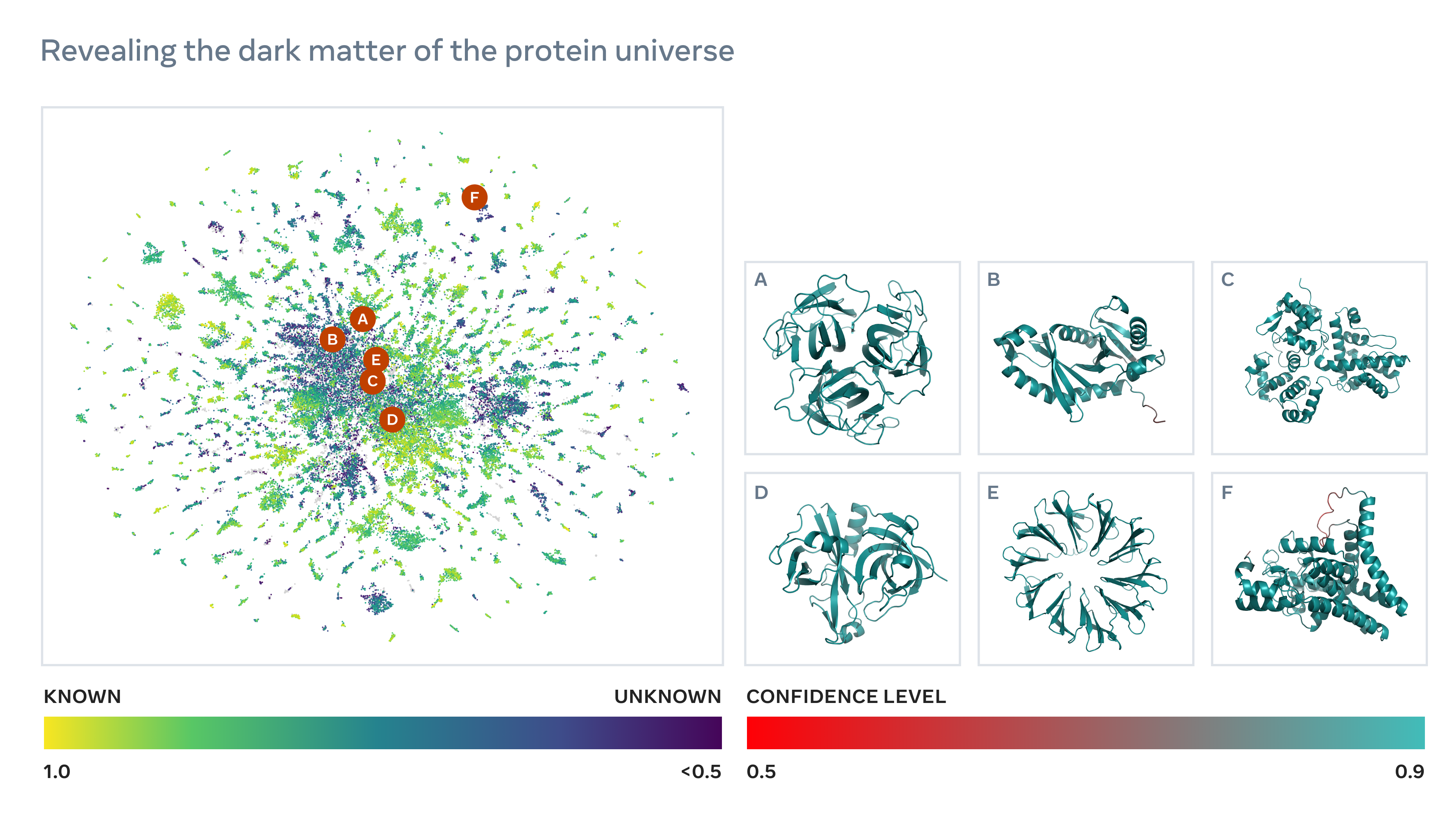
Von Metas System vorhergesagte Proteinstrukturen. Bildnachweis: Meta
Vorausschauen
Während die Interessen von OpenBioML breit gefächert sind (und sich ausdehnen), sagt Mostaque, dass sie durch den Wunsch vereint sind, „das positive Potenzial des maschinellen Lernens und der KI in der Biologie zu maximieren“, in der Tradition der offenen Forschung in Wissenschaft und Medizin.
„Wir wollen es Forschern ermöglichen, mehr Kontrolle über ihre experimentelle Pipeline für aktives Lernen oder Modellvalidierungszwecke zu erlangen“, fuhr Mostaque fort. „Wir versuchen auch, den Stand der Technik mit zunehmend allgemeinen Biotech-Modellen voranzutreiben, im Gegensatz zu den spezialisierten Architekturen und Lernzielen, die derzeit den größten Teil der Computerbiologie charakterisieren.“
Aber – wie man es von einem VC-gestützten Startup erwarten könnte, das kürzlich über 100 Millionen US-Dollar gesammelt hat – sieht Stability AI OpenBioML nicht als rein philanthropische Anstrengung. Mostaque sagt, dass das Unternehmen offen dafür ist, die Kommerzialisierung von Technologie von OpenBioML zu untersuchen, „wenn sie fortgeschritten genug und sicher genug ist und wenn die Zeit reif ist“.