
Aktualisierung
Sandra Rivera hat die Bühne betreten, um zu skizzieren, dass sie über die neue Rechenzentrums-Roadmap, den Total Addressable Market (TAM) für Intels Rechenzentrumsgeschäft, das sie auf 110 Milliarden US-Dollar schätzt, und Intels Bemühungen im Bereich der KI berichten wird.
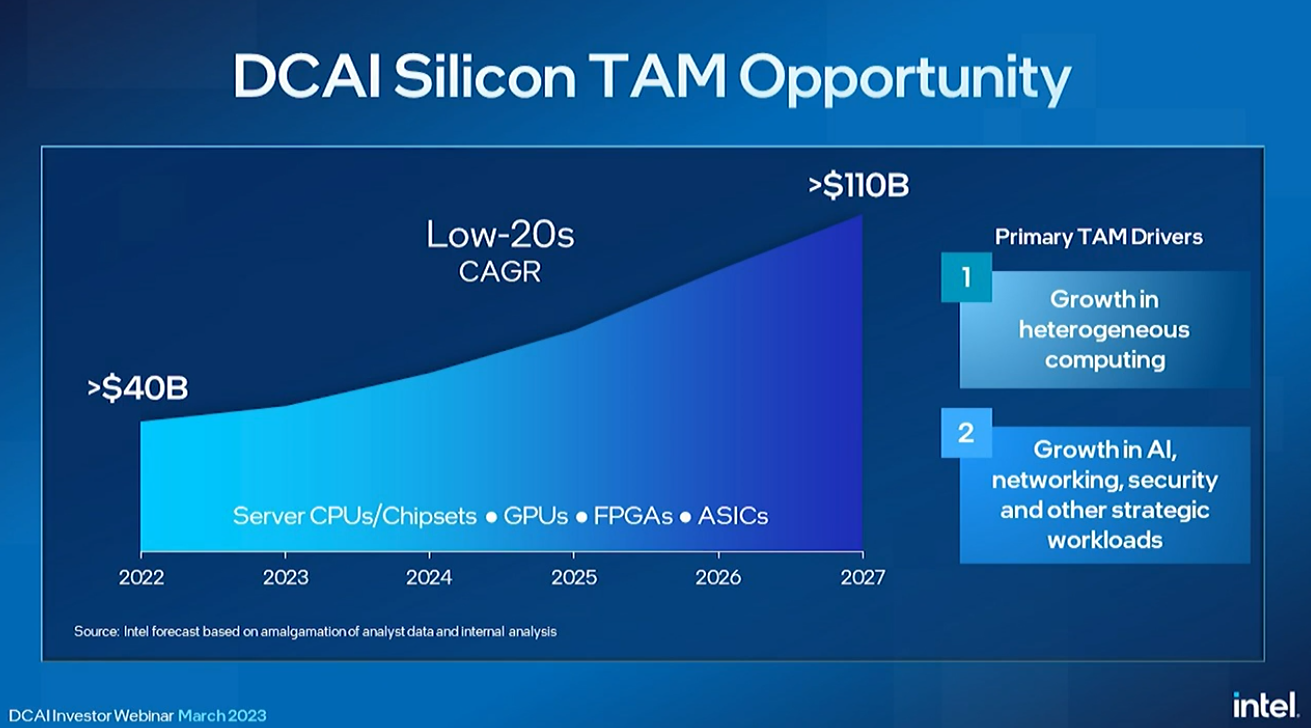
Rivera erklärte, dass Intel oft durch die Linse von CPUs schaut, um seinen Gesamtumsatz aus Rechenzentren zu messen, aber jetzt seinen Umfang erweitert, um verschiedene Arten von Rechenleistung wie GPUs und kundenspezifische Beschleuniger einzubeziehen.
Intel arbeitet an der Entwicklung eines breiten Portfolios von Softwarelösungen zur Ergänzung seines Chip-Portfolios.
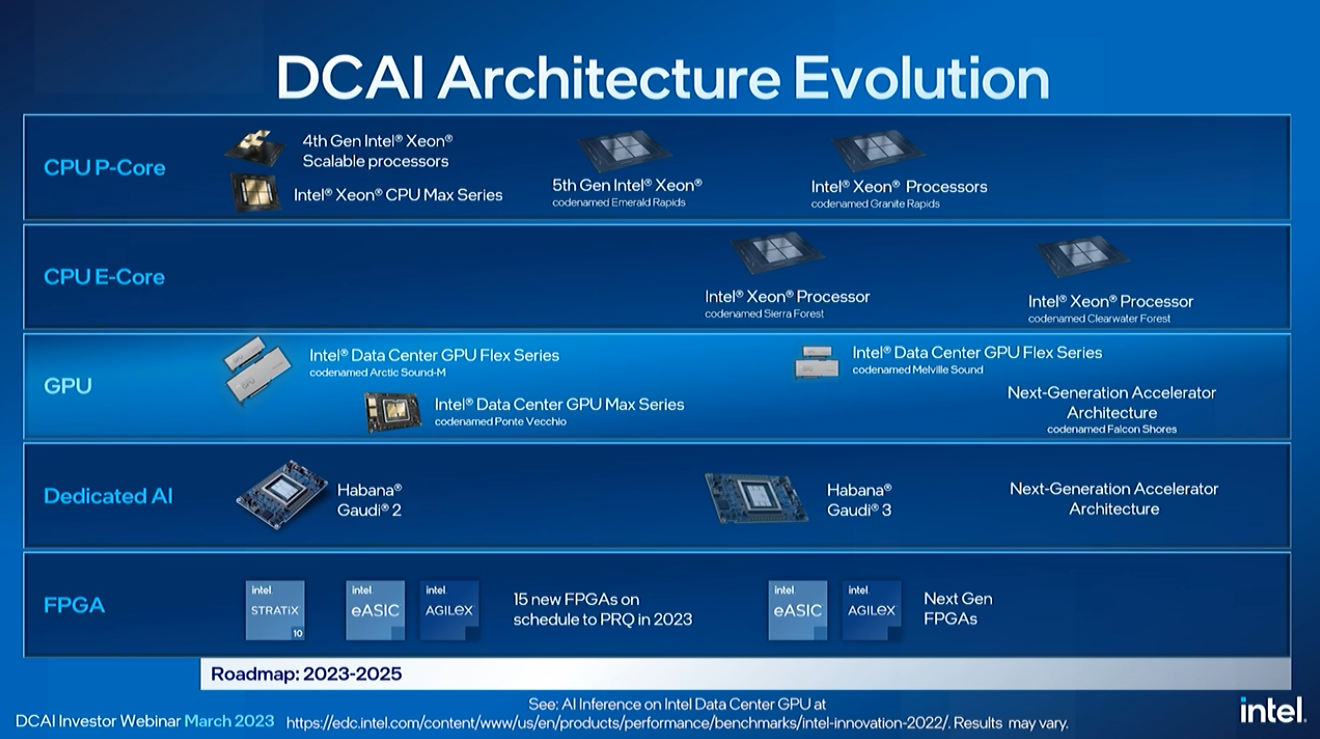
Intel hat seine Xeon-Roadmap in zwei Linien aufgeteilt, eine mit P-Cores und eine mit E-Cores, wobei jede ihre eigenen Vorteile hat. Die P-Core (Performance Core)-Modelle sind die traditionellen Xeon-Rechenzentrumsprozessoren mit nur Kernen, die die volle Leistung von Intels schnellsten Architekturen liefern. Diese Chips sind für höchste Leistung pro Kern und KI-Workload ausgelegt. Sie werden auch mit Beschleunigern kombiniert, wie wir bei Sapphire Rapids sehen.
Die E-Core (Efficiency Core)-Reihe besteht aus Chips mit nur kleineren Effizienzkernen, ähnlich wie wir sie bei Intels Consumer-Chips sehen, die auf einige Funktionen wie AMX und AVX-512 verzichten, um eine höhere Dichte zu bieten. Diese Chips sind auf hohe Energieeffizienz, Kerndichte und Gesamtdurchsatz ausgelegt, was für Hyperscaler attraktiv ist. Die Xeon-Prozessoren von Intel werden keine Modelle mit sowohl P-Kernen als auch E-Kernen auf demselben Silizium haben, daher handelt es sich um unterschiedliche Familien mit unterschiedlichen Anwendungsfällen.
Die E-Kerne wurden entwickelt, um ARM-Konkurrenten zu bekämpfen.

Intel hat seine Sapphire Rapids mit über 450 Design Wins und mehr als 200 Designs, die von Top-OEMs ausgeliefert werden, auf den Markt gebracht. Intel behauptet eine 2,9-fache Effizienzsteigerung von Generation zu Generation.

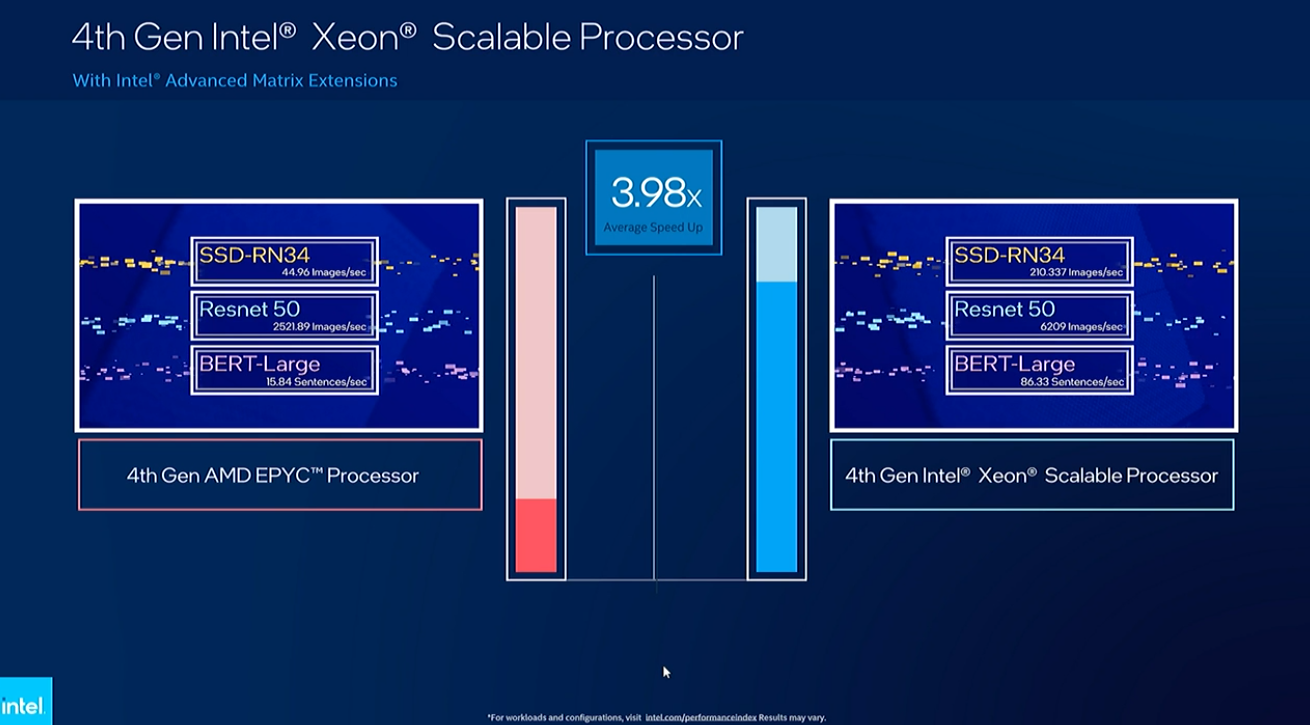
Intels Sapphire Rapids unterstützt seine KI-verstärkende AMX-Technologie, die verschiedene Datentypen und Vektorverarbeitung verwendet, um die Leistung zu steigern. Lisa Spelman führte eine Demo durch, die zeigte, dass ein 48-Core-Sapphire Rapids einen 48-Core-EPYC-Genoa in einer Vielzahl von KI-Workloads um das 3,9-fache schlägt.
Rivera zeigte uns den bevorstehenden Emerald Rapids-Chip des Unternehmens. Emerald Rapids der nächsten Generation von Intel soll im vierten Quartal dieses Jahres erscheinen, was ein komprimierter Zeitrahmen ist, da Sapphire Rapids erst vor wenigen Monaten auf den Markt kam.
Intel sagt, dass es eine schnellere Leistung, eine bessere Energieeffizienz und, was noch wichtiger ist, mehr Kerne als sein Vorgänger bieten wird. Intel sagt, dass es das Emerald Rapids-Silizium im eigenen Haus hat und dass die Validierung wie erwartet voranschreitet, wobei das Silizium seine Leistungs- und Leistungsziele entweder erreicht oder übertrifft.

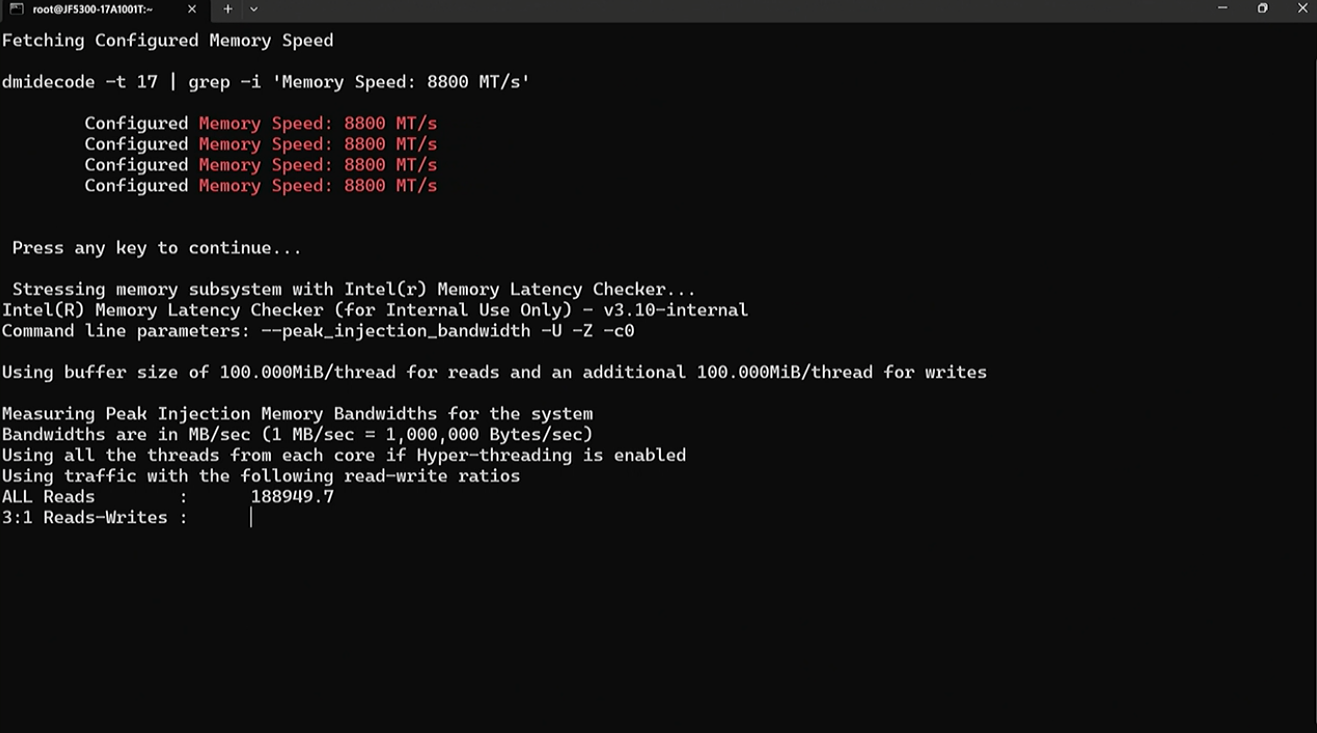
Granite Rapids wird 2024 eintreffen, dicht gefolgt von Sierra Forest. Intel wird diesen Chip nach dem „Intel 3“-Prozess herstellen, einer stark verbesserten Version des „Intel 4“-Prozesses, dem die für Xeon erforderlichen High-Density-Bibliotheken fehlten. Dies ist der erste P-Core-Xeon auf „Intel 3“, und er wird mehr Kerne als Emerald Rapids, eine höhere Speicherbandbreite von DDR5-8800-Speicher und andere nicht näher bezeichnete I/O-Innovationen aufweisen. Dieser Chip wird jetzt an Kunden bemustert.

Intel hat während seines Webinars einen Granite Rapids mit zwei Sockeln vorgeführt, der eine unglaubliche DDR5-Speicherbandbreite von 1,5 TB/s bietet, eine angebliche Spitzenbandbreitenverbesserung von 80 % gegenüber vorhandenem Serverspeicher. Zum Vergleich: Granite Rapids bietet mehr Durchsatz als Nvidias 960-GB/s-Grace-CPU-Superchip, der speziell für die Speicherbandbreite entwickelt wurde, und mehr als AMDs Dual-Socket-Genoa, das einen theoretischen Spitzenwert von 920 GB/s hat.
Intel hat dieses Kunststück mit DDR5-8800 Multiplexer Combined Rank (MCR) DRAM vollbracht, einem neuen Typ von bandbreitenoptimiertem Speicher, den es erfunden hat. Intel hat diesen Speicher bereits mit SK hynix vorgestellt.
Hier können wir die Demo sehen.
Intels E-Core-Roadmap beginnt mit dem Sierra Forest mit 144 Kernen, der 256 Kerne in einem einzigen Dual-Socket-Server bereitstellen wird. Die 144 Kerne des Xeon Sierra Forest der fünften Generation überwiegen auch AMDs 128-Kern EPYC Bergamo in Bezug auf die Anzahl der Kerne, übernehmen aber wahrscheinlich nicht die Führung bei der Anzahl der Threads – Intels E-Cores für den Verbrauchermarkt sind Single-Threaded, aber die Ob die E-Cores für das Rechenzentrum Hyperthreading unterstützen, hat das Unternehmen nicht verraten. AMD hat mitgeteilt, dass der 128-Kern-Bergamo hyperthreaded ist und somit insgesamt 256 Threads pro Socket bereitstellt.
Laut Rivera hat Intel das Silizium eingeschaltet und ein Betriebssystem in weniger als 18 Stunden hochgefahren (ein Unternehmensrekord). Dieser Chip ist das führende Vehikel für den „Intel 3“-Prozessknoten, daher ist der Erfolg von größter Bedeutung. Intel ist zuversichtlich genug, dass es die Chips bereits seinen Kunden bemustert und alle 144 Kerne auf der Veranstaltung in Aktion vorgeführt hat. Intel zielt mit den E-Core-Xeon-Modellen zunächst auf bestimmte Arten von Cloud-optimierten Workloads ab, erwartet jedoch, dass sie für eine weitaus breitere Palette von Anwendungsfällen übernommen werden, sobald sie auf dem Markt sind.

Spelman kehrte zurück, um uns alle 144 Kerne des Sierra-Forest-Chips in einer Demo zu zeigen.
Rivera hat jetzt den Nachfolger von Sierra Forest angekündigt – Clearwater Forest. Intel hat über die Veröffentlichung im Jahr 2025 hinaus nicht viele Details preisgegeben, sagte jedoch, dass es den 18A-Prozess für den Chip verwenden wird, nicht den 20A-Prozessknoten, der ein halbes Jahr zuvor eintrifft. Dies wird der erste Xeon-Chip mit dem 18A-Prozess sein.

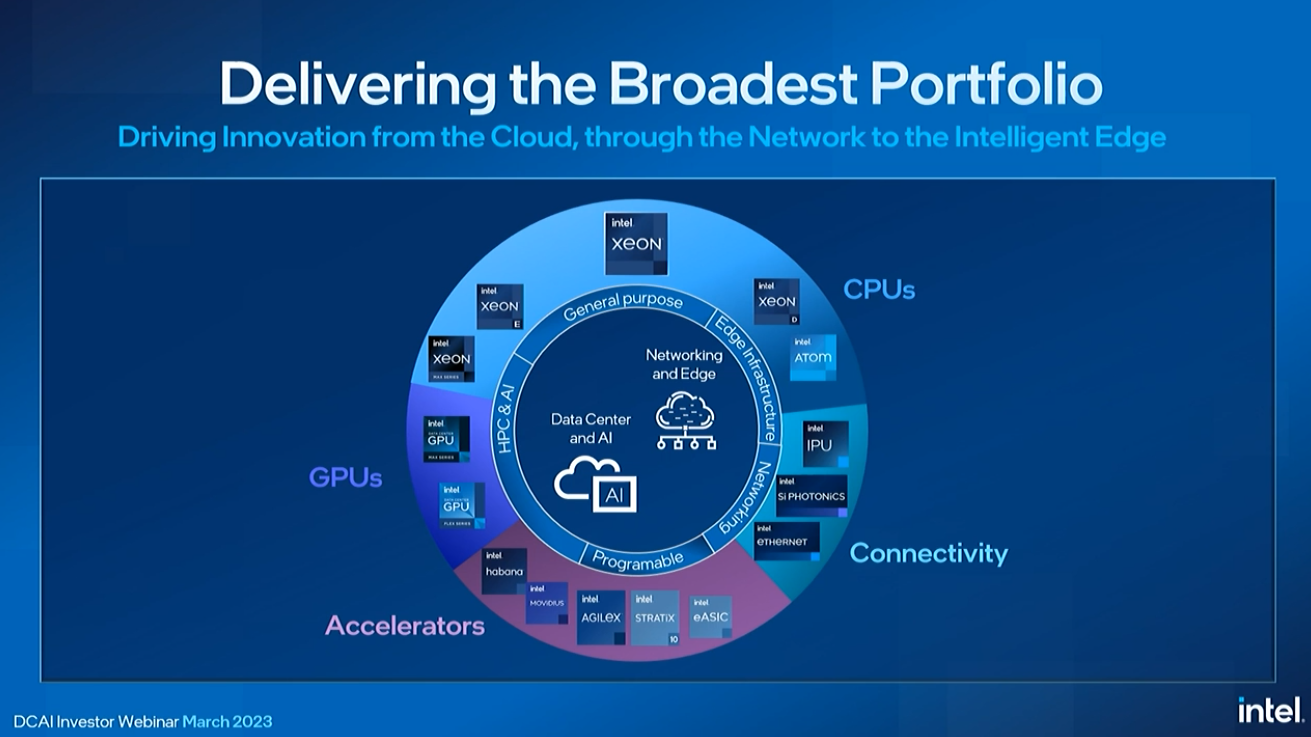
Intel hat auch eine vollständige Liste anderer Chips für KI-Workloads. Intel wies darauf hin, dass es in diesem Jahr 15 neue FPGAs auf den Markt bringen wird, ein Rekord für seine FPGA-Gruppe. Wir haben noch keine großen Gewinne mit den Gaudi-Chips gehört, aber Intel entwickelt sein Lineup weiter und hat einen Beschleuniger der nächsten Generation auf der Roadmap. Der KI-Beschleuniger Gaudi 2 wird ausgeliefert und Gaudi 3 wurde mit Klebeband versehen.
Rivera skizzierte die umfassenden Bemühungen von Intel im KI-Bereich. Intel prognostiziert, dass KI-Workloads weiterhin überwiegend auf CPUs ausgeführt werden, wobei 60 % aller Modelle, hauptsächlich die kleinen bis mittelgroßen Modelle, auf CPUs ausgeführt werden. Inzwischen werden die großen Modelle etwa 40 % der Workloads ausmachen und auf GPUs und anderen benutzerdefinierten Beschleunigern laufen.

Intel arbeitet mit Inhaltsanbietern zusammen, um KI-Arbeitslasten für Videostreams auszuführen, und KI-basierte Berechnungen können Daten beschleunigen, komprimieren und verschlüsseln, die sich über das Netzwerk bewegen, was alles auf einer einzigen Sapphire Rapids-CPU erfolgt.

CPUs eignen sich auch gut für kleinere Inferenzmodelle, aber diskrete Beschleuniger sind für größere Modelle wichtig. Intel nutzt seine GPUs Gaudi und Ponte Vecchio, um diesen Markt anzusprechen. Hugging Face sagte kürzlich, Gaudi habe ihm die 3-fache Leistung in der Hugging Face Transformers-Bibliothek gegeben.

Rivera hat in einem Cluster-Benchmark Intels Skalierungseffizienz von 97 % angepriesen.

Greg Lavendar von Intel, SVP und CTO bei Intel, nahm an dem Webcast teil, um die Demokratisierung von KI zu diskutieren.

Intel arbeitet auch daran, ein Software-Ökosystem für KI aufzubauen, das mit Nvidias CUDA konkurriert. Dazu gehört auch ein End-to-End-Ansatz, der Silizium, Software, Sicherheit, Vertraulichkeit und Vertrauensmechanismen an jedem Punkt des Stacks umfasst.

Intel strebt einen offenen Multi-Vendor-Ansatz an, um eine Alternative zu Nvidias CUDA bereitzustellen.

Intels Bemühungen mit OneAPI gehen weiter, mit 6,2 Millionen aktiven Entwicklern, die die Intel-Tools verwenden.

Intel hat SYCLomatic eingeführt, um CUDA-Code automatisch zu SYCL zu migrieren.

Lavender skizzierte auch die Bemühungen des Unternehmens, Skalierung bereitzustellen und die Entwicklung über die Intel Developer Cloud zu beschleunigen. Intel hat seit der Ankündigung des Programms im Jahr 2021 die Zahl der Benutzer vervierfacht. Und damit übergab er den Staffelstab wieder an Sandra.
Rivera dankte dem Publikum für die Teilnahme am Webinar und teilte auch eine Zusammenfassung der wichtigsten Ankündigungen mit.
Zusammenfassend hat Intel angekündigt, dass Sierra Forest, sein Effizienz-Xeon der ersten Generation, mit unglaublichen 144 Kernen ausgestattet sein wird und somit eine bessere Kerndichte bieten wird als die konkurrierenden 128-Kern-Chips EPYC Bergamo von AMD. Das Unternehmen hat den Chip auch in einer Demo angeteasert. Intel enthüllte auch die ersten Details von Clearwater Forest, seinem Effizienz-Xeon der zweiten Generation, der 2025 debütieren wird. Intel hat seinen 20A-Prozessknoten für den leistungsstärkeren 18A für diesen neuen Chip übersprungen, was Bände über sein Vertrauen in die Gesundheit seines Prozessors spricht zukünftiger Knoten.
Intel präsentierte auch mehrere Demos, einschließlich Kopf-an-Kopf-KI-Benchmarks gegen AMDs EPYC Genoa, die einen 4-fachen Leistungsvorteil für Xeon in einem Kopf-an-Kopf-Rennen von zwei 48-Kern-Chips zeigen, und einen Speicherdurchsatz-Benchmark, der die nächste gen Granite Rapids Xeon mit unglaublichen 1,5 TB/s Bandbreite in einem Dual-Socket-Server.
Dies ist eine Veranstaltung für Investoren, daher wird das Unternehmen jetzt ein Q&A durchführen, das sich auf die finanzielle Seite der Präsentation konzentriert. Wir werden uns hier nicht auf den Abschnitt „Fragen und Antworten“ konzentrieren, es sei denn, die Antworten beziehen sich besonders auf die Hardware, die unsere Stärke ist. Wenn Sie mehr an der finanziellen Seite des Gesprächs interessiert sind, können Sie das tun Sehen Sie sich das Webinar hier an.
