
Für Forscher kann das Lesen wissenschaftlicher Arbeiten immens zeitaufwändig sein. Einer Umfrage zufolge verbringen Wissenschaftler jede Woche sieben Stunden damit, nach Informationen zu suchen. Eine andere Umfrage legt nahe, dass systematische Literaturrecherchen – wissenschaftliche Synthesen der Beweise zu einem bestimmten Thema – für ein fünfköpfiges Forschungsteam durchschnittlich 41 Wochen dauern.
Aber es muss nicht so sein.
Das ist zumindest die Botschaft von Andreas Stuhlmüller, dem Mitgründer eines KI-Startups. Entlocken, das als „Forschungsassistent“ für Wissenschaftler und Forschungs- und Entwicklungslabore konzipiert ist. Mit Unterstützern wie Fifty Years, Basis Set, Illusion und den Angel-Investoren Jeff Dean (Chefwissenschaftler von Google) und Thomas Ebeling (ehemaliger CEO von Novartis) entwickelt Elicit ein KI-gestütztes Tool, um die mühsameren Aspekte der Literaturrecherche zu abstrahieren.
“Entlocken ist ein Forschungsassistent, der wissenschaftliche Forschung mit Sprachmodellen automatisiert“, sagte Stuhlmüller gegenüber TechCrunch in einem E-Mail-Interview. „Konkret automatisiert es die Literaturrecherche, indem es relevante Artikel findet, wichtige Informationen über die Studien extrahiert und die Informationen in Konzepten organisiert.“
Elicit ist ein gewinnorientiertes Unternehmen, das aus Ought hervorgegangen ist, einer gemeinnützigen Forschungsstiftung, die 2017 von Stuhlmüller, einem ehemaligen Forscher am Computer- und Kognitionslabor von Stanford, ins Leben gerufen wurde. Der andere Mitbegründer von Elicit, Jungwon Byun, trat dem Startup im Jahr 2019 bei, nachdem er das Wachstum beim Online-Kreditunternehmen Upstart geleitet hatte.
Mithilfe einer Vielzahl von Modellen sowohl von Erst- als auch von Drittanbietern sucht und entdeckt Elicit Konzepte in verschiedenen Veröffentlichungen und ermöglicht es Benutzern, Fragen zu stellen wie „Was sind die Auswirkungen von Kreatin?“ oder „Welche Datensätze wurden zur Untersuchung des logischen Denkens verwendet?“ und erhalten Sie eine Liste mit Antworten aus der wissenschaftlichen Literatur.
„Durch die Automatisierung des systematischen Überprüfungsprozesses können wir den akademischen und industriellen Forschungseinrichtungen, die diese Bewertungen erstellen, sofort Kosten- und Zeiteinsparungen bescheren“, sagte Stuhlmüller. „Indem wir die Kosten ausreichend senken, erschließen wir neue Anwendungsfälle, die bisher unerschwinglich waren, wie etwa Just-in-Time-Updates, wenn sich der Wissensstand in einem Bereich ändert.“
Aber Moment, könnte man sagen – neigen Sprachmodelle nicht dazu, Dinge zu erfinden? Tatsächlich tun sie es. Metas Versuch eines Sprachmodells zur Rationalisierung der wissenschaftlichen Forschung, Galacticawurde nur drei Tage nach dem Start entfernt, als sich herausstellte, dass sich das Modell häufig auf gefälschte Forschungsarbeiten bezog, die richtig klangen, aber nicht den Tatsachen entsprachen.
Stuhlmüller behauptet jedoch, Elicit habe Schritte unternommen, um sicherzustellen, dass seine KI zuverlässiger sei als viele der speziell entwickelten Plattformen auf dem Markt.
Zum einen zerlegt Elicit die komplexen Aufgaben, die seine Modelle ausführen, in „für den Menschen verständliche“ Teile. Dadurch kann Elicit beispielsweise wissen, wie oft verschiedene Modelle etwas erfinden, wenn sie Zusammenfassungen erstellen, und Benutzern anschließend dabei helfen, zu erkennen, welche Antworten wann überprüft werden müssen.
Elicit versucht auch, die allgemeine „Vertrauenswürdigkeit“ einer wissenschaftlichen Arbeit zu berechnen, indem Faktoren wie die Frage, ob die in der Forschung durchgeführten Studien kontrolliert oder randomisiert waren, die Quelle der Finanzierung und potenzieller Konflikte sowie die Größe der Studien berücksichtigt werden.
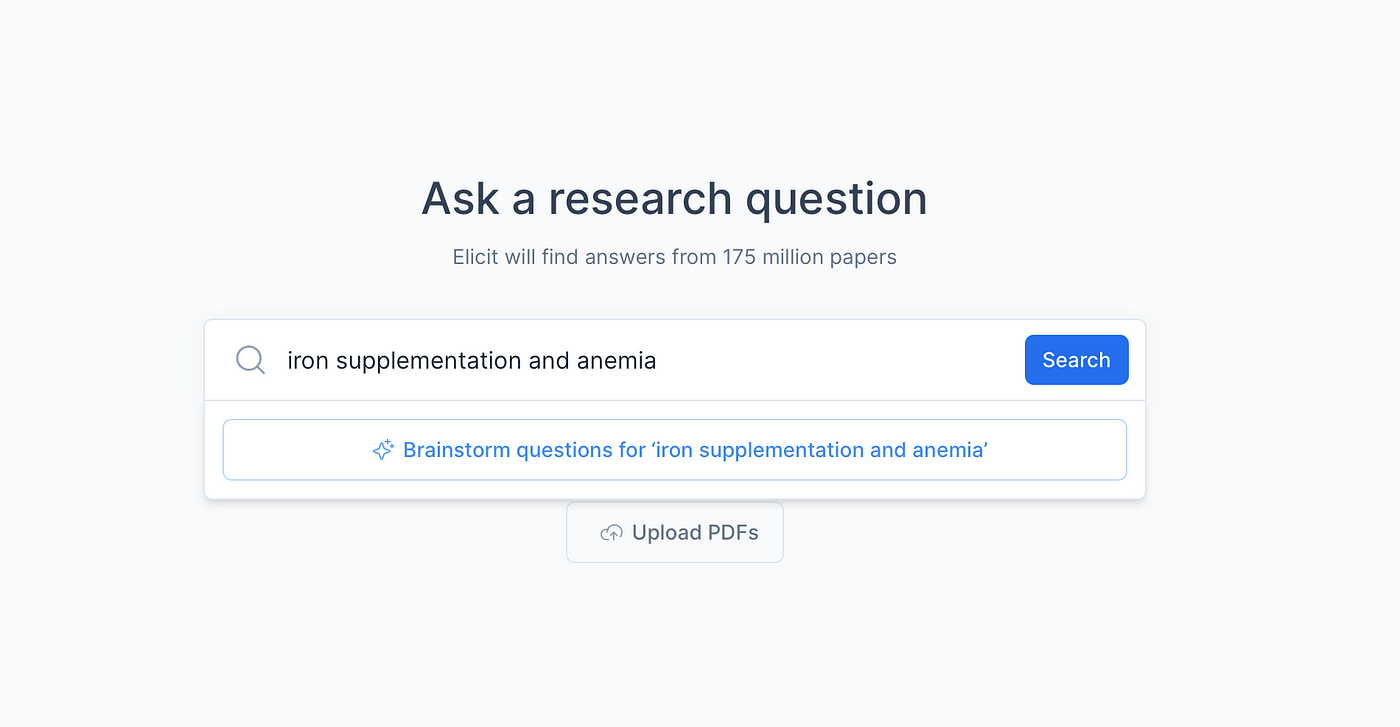
Elicits Suchtool für KI-Literatur. Bildnachweis: Entlocken
„Wir machen keine Chat-Schnittstellen“, sagte Stuhlmüller. „Elicit-Benutzer wenden Sprachmodelle als Batch-Jobs an … Wir generieren Antworten nicht nur mithilfe von Modellen, sondern verknüpfen die Antworten immer mit der wissenschaftlichen Literatur, um Halluzinationen zu reduzieren und die Überprüfung der Modellarbeit zu vereinfachen.“
Ich bin nicht unbedingt davon überzeugt, dass Elicit einige der Hauptprobleme gelöst hat, mit denen Sprachmodelle heute aufgrund ihrer Widerspenstigkeit zu kämpfen haben. Aber seine Bemühungen scheinen sicherlich das Interesse – und vielleicht sogar das Vertrauen – der Forschungsgemeinschaft geweckt zu haben.
Stuhlmüller gibt an, dass jeden Monat mehr als 200.000 Menschen Elicit von Organisationen wie der Weltbank, Genentech und Stanford nutzen, was einem dreifachen Wachstum gegenüber dem Vorjahr entspricht (ab Januar 2023). „Unsere Benutzer verlangen, für leistungsfähigere Funktionen zu zahlen und Elicit in größerem Umfang auszuführen“, fügte er hinzu.
Vermutlich ist es diese Dynamik, die zur ersten Finanzierungsrunde von Elicit führte – einer 9-Millionen-Dollar-Tranche unter der Führung von Fifty Years. Der Plan besteht darin, den Großteil des neuen Geldes in die Weiterentwicklung des Elicit-Produkts sowie in die Erweiterung des Elicit-Teams aus Produktmanagern und Softwareentwicklern zu stecken.
Aber was hat Elicit vor, um Geld zu verdienen? Gute Frage – und eine, die ich Stuhlmüller direkt gestellt habe. Er verwies auf die kostenpflichtige Stufe von Elicit, die diese Woche eingeführt wurde und es Benutzern ermöglicht, in größerem Umfang nach Artikeln zu suchen, Daten zu extrahieren und Konzepte zusammenzufassen, als dies mit der kostenlosen Stufe möglich ist. Die längerfristige Strategie besteht darin, Elicit zu einem allgemeinen Tool für Recherche und Argumentation auszubauen – eines, für das ganze Unternehmen Geld ausgeben würden.
Ein mögliches Hindernis für den kommerziellen Erfolg von Elicit sind Open-Source-Bemühungen wie das Open Language Model des Allen Institute for AI, die darauf abzielen, ein kostenlos nutzbares, für die Wissenschaft optimiertes, großes Sprachmodell zu entwickeln. Doch Stuhlmüller sagt, dass er Open Source eher als Ergänzung denn als Bedrohung ansieht.
„Der Hauptkonkurrent ist derzeit die menschliche Arbeitskraft – Forschungsassistenten, die angestellt werden, um mühsam Daten aus Arbeiten zu extrahieren“, sagte Stuhlmüller. „Wissenschaftliche Forschung ist ein riesiger Markt und Forschungs-Workflow-Tools haben keine großen etablierten Anbieter. Hier werden völlig neue AI-First-Workflows entstehen.“